A quick guide to Artificial Intelligence for data designers and curious minds.
Words by Pau Aleikum — Founding partner of Domestic Data Streamers
I want to thank Boldtron, Eduard Corral, and Víctor Perez for their constant contribution and generosity on the path to Artificial wisdom.
This article is the first in a series of articles about how the latest artificial technologies can be integrated and impact the data visualisation and information design industry.
INTRODUCTION
Earlier this year, I was lucky enough to be close to some of the first Dalle2 beta testers, and I’ve been able to follow the evolution of text-to-image tools from the very early stages of their public release. The first thing I have learned is how fast written content around this topic becomes obsolete, so that said, I’ll do my best to see that in a couple of months, at least 50% of what I share here is not ancient history.
First, a quick disclaimer on where we stand as Domestic Data Streamers regarding Artificial intelligence: even if text-to-image is a fantastic tool that is creating blasting results, we still believe the technology we are using is quite dumb; as you will soon discover, you shouldn’t be misled by the term artificial intelligence, it’s not that clever.
Noam Chomsky put it amazingly well in this article, summarising that; the technology we are using only works on statistics, it doesn’t “know” anything nor understand it. It follows orders of very complex mathematical models, but there is still no such thing as “it.” As Chomsky explains, if you put a camera in front of a window with these AIs for a year, the algorithm can predict what will happen next in the window. However, the intelligent thing would be knowing not “what” but “why” this will happen, and today’s AI is still a long way from this kind of intelligence.
- THE THREE GIANTS
I will make a very simplified summary for people who are just getting started with the text-to-image tools. There are many programmes available, but I will talk about the three most prolific actors today; Dalle2 by OpenAi (owned by Microsoft), Stable Diffusion, and Midjourney.
In my experience, Stable Diffusion is much better at details and quality, and Dalle2 is better at composing complex scenes and photographic finishes. Midjourney, on the other hand, has mastered a specific style; it is easy to spot with a recently trained eye whether an image has been created with Midjourney, but with every new model, you can see how it gets closer to the others. The latest updated version (v4) is genuinely unique and may well change the standings on the image creation leaderboard.
The results you get from Midjourney are different from Dalle2 and Stable because of a conscious decision from their team. David Holz (Midjourney’s CEO) has repeatedly explained that he doesn’t want the software to create images that can be mistaken for authentic images because of the potential that it may support fake news or other misuses of the technology. This is not only worrying Midjourney, last month Adobe, Leika, and Canon also started working together on the development of a new authentication software that can verify that an image has been taken with a camera and has not been touched by AI. Yes, a bit dystopian; it feels like asking every person you meet for a birth certificate because otherwise, how can you be sure it’s a real human being? (Blade Runner fans unite.)
Now, going back to Stable Diffusion, its main characteristic is that it is open source, you can access the model, you can train it on your own with new words, objects, and ideas, and you can run it on your independent computer without any corporate supervision or internet connection, and you can download it for Mac and for PC. That’s both a blessing and a danger, of course. As the algorithm runs without any barrier or censorship, all kinds of creations have emerged, and we only need to go through a few Reddit forums to see what’s coming up…
But if you don’t want to, or can’t set up your computer to run the algorithm, you can always use Stable Diffusion within a digital framework; you can use Stable Cog, AI Playground or Dreamstudio, and both of them work amazingly well, but also bear in mind that they have different costs. Here you have a quick price comparison:
AI Playground (Stable Diffusion): $0,00025/image ($10/month for 2.000 images a day)
Midjourney: $30/month for unlimited images
Dreambooth (Stable Diffusion): $0,01/image ($10 for 1.000 image generations)
Dalle2: $0,032/image ($15 for 460 image generations)
2- TOOL CATALOGUE
Now, having introduced our three key players, I want to introduce some other tools that have been essential to my process of better understanding this technology:
2.1- Prompt Portals
My favourite, without a doubt, is Krea.ai; it’s a platform in constant transformation that enables you to find the best results for Stable Diffusion; this is a must. Through this platform, you will be able to navigate through a Pinterest-style environment, whilst discovering the prompts behind each image. That’s the basis of any learning process, copy and replicate what you like and what you love, test the prompts, modify them and explore how that affects your creations. Still, Krea is working on building up a platform similar to AI Playground but with much greater capabilities; if I were to recommend you follow the evolution of just one platform, this would be the one. You can also find Public Prompts, a platform developed by a junior medical doctor from Lebanon trying to fight against the prompt marketplace.
2.2- Prompt Books
This is the panacea not only to learning but also to getting inspired; the first prompt book I ever read was one on Dalle2 and it changed my understanding of the tool and encouraged me to experiment on a whole new level. In the studio, we’ve now developed our own Basic Prompt Book and another explicitly focused for Data Visualization Prompts. I strongly recommend that as an exercise you produce your own. In the process, you will learn what works and what doesn’t; for my students and work colleagues it’s been a game changer.
2.3- Reversing Prompts
Sometimes to truly understand something, you have to break it. In the case of text-to-image, I have used two methods; the first is to reverse engineer an image and search for the prompt that created it. Img2prompt and CLIP do precisely that. The other way is to understand how an algorithm has been trained; which images are the ones that define what the algorithm will build? For that, we have Have I Been Trained?, I believe this method is truly important because it shows how as we are using these tools, we are drawing from millions of images by other artists, photographers, and random people that build up the data sets from which we generate new creations (or we could call them spawns).
2.4- Prompt creators
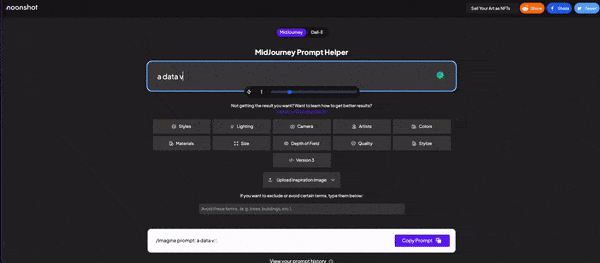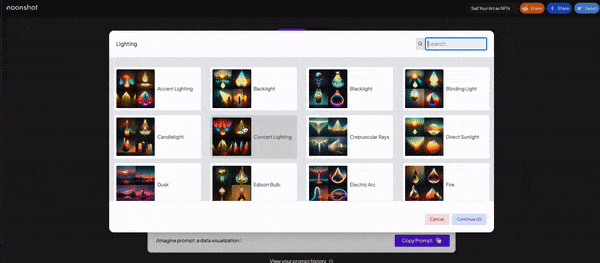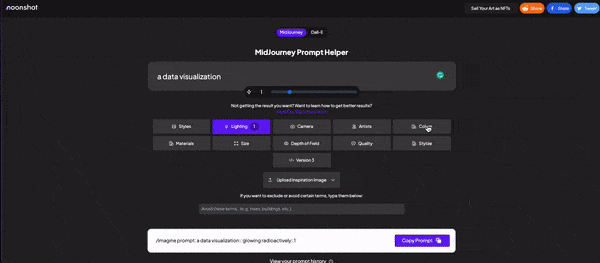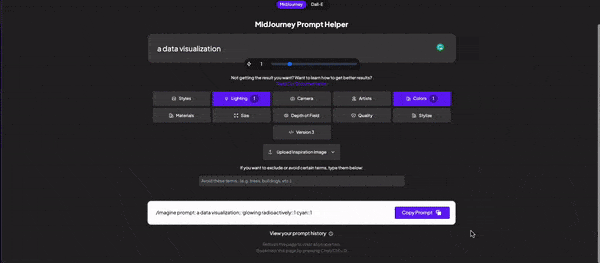
Now, you already understand the main idea behind text-to-image, but you will need assistance to create the best prompts to keep innovating and improving your image results. For that, we have several other software we can use. We’ve got Phrase models that bring you a lot of different variables to think about. For Dalle2 specifically, I recommend this chrome extension; it turns the prompting process into a click-on experience. For Midjourney you’ve got Noonshot which is just amazing in terms of how technical you can get. If none of these convince you, you can also test Promptmania.
2.5- Technical Semantics
If you have arrived here, I’m sure you have come to realise the importance of language use; it is not the same saying I want “a cyberpunk woman portrait” as a “highly detailed portrait of a post-cyberpunk south african young lady by Akihiko Yoshida, Greg Tocchini, 4k resolution, mad max inspired, pastel pink, light blue, brown, white and black color scheme with south african symbols and graffiti’’ the more specific the prompts, the better the results, so I recommend you search for the correct vocabulary to define each aspect, from painting techniques to cinematic techniques, to kinds of photographic film you can use. Again you can find some of these treatments in our promptbooks. Still, you’ll also benefit greatly from exploring references that are outside of the classic prompt books, and finding specialised semantics from the field you truly want to study, from the kinds of camera to the films you use to shoot, art movements, painting techniques.
2.6- Enhancing
At a certain point, you will need to improve the quality of the images you create; the truth is that all the text-to-image tools right now give you very standard resolution images Dalle2 has reduced a lot to 1024px x 1024px, Midjourney can upscale it up to 1664 x 1664. Of course, Stable Diffusion can work on building much bigger images if you programme it; we have diffused images at 4k already in the studio, and Boldtron is up to 6k, but you will need to build up a tool for that. If needed, you can use other essential upscaling tools. I use Photoshop, but you can use Bigjpg or VanceAI for that.
Other than the size of the image, you may be looking to enhance a specific part of the image, sharpen the borders, or focus on a blurry face. As I said before Dalle2 is impressive for creating a scene, but it sucks when making more than one face at a time. Luckily we can use tools like GFPGAN or FaceRestoration to enhance them with good results. And this has become a fundamental part of the work of building new images. The best is always to cross over tools.
3- DATA VISUALISATION
Right now, we are in the early stages of understanding how this can be a tool for us data storytellers, and we have started from the very beginning, with the study of semantics and quantitative semantics. In this prompt book, you will find the research we’ve carried out on some of the essential qualities that you can find in a visualisation, shape, colour, density, contrast and all of the basics that our beloved cartographer Jaques Bertin put up as a basis of data visualisation. In the book, you will find a simple guide to creating your semantic fields and some early experiments we have done using them, like the ones below.
4- POTENTIAL USES
I’m confident that these tools will become mainstream as they get easier to use, better designed, more centralised (sadly), and more result oriented. At present we are at a point where most of the users are early adopters, still learning and experimenting, without showing hard intention behind it. I’ve started to see the first cases that point out the beginning of the tool’s potential, like this one, working on civic engagement around the future architecture of a place. Text-to-image has the power to eliminate interface barriers and, second, the potential to imagine almost anything that is in the mind of the users. That puts enormous potential in the hands of people who often go unheard and disempowered by the lack of projection and design tools. This is just one case, but soon we will disclose more possibilities that we are already exploring in our studio.
5- CONCERNS
These tools have opened a massive debate on authorship and the threat they pose to many creative professions, so I will share the main insights behind two of the best (and somehow antagonistic) articles I’ve read so far on the topic.
This one from Future History by Daniel Jeffries, responds to the idea that AI is stealing “art” and how to manage intellectual property. Here is an excerpt:
“There’s a growing fear of AI training on big datasets where they didn’t get the consent of every single image owner in their archive. This kind of thinking is deeply misguided and it reminds me of early internet critics who wanted to force people to get the permission of anyone they linked to. Imagine I had to go get the permission of Time magazine to link to them in this article, or Disney, or a random blog post with someone’s information I couldn’t find. It would turn all of us into one person IP request departments. Would people even respond? Would they care? What if they were getting millions of requests per day? It wouldn’t scale. And what a colossal waste of time and creativity!”
The second article is called Towards a Sustainable Generative AI Revolution by Javier Ideami. It offers a more profound insight into how these models work compared to our brains and builds a critical argument around how these AI models have been constructed without the artist’s consent. Summarizing his summary:
The good news:
- Generative AI won’t replace human creativity. It will enhance it.
- This technology demystifies creativity. Think of what Edison said: Genius is 99% perspiration (combination, recombination, productive work and experimentation) and 1% inspiration (establishing the seeds, polishing, etc). Thanks to this new technology, we now realize that we can automate a large percentage of the creative process.
- Although some jobs are in danger, it is also highly likely that new roles that we cannot yet imagine, will emerge from the need to manage and interact with this technology.
- A good number of people who may not be professional artists, but that have a natural predisposition to exercise their creative muscles, will thrive with this new technology. They will strengthen those muscles in faster and easier ways, and they will enjoy new opportunities to augment and amplify their creative potential.
The tricky:
- AI generative systems are only possible because of the giant datasets of images, videos, and text that are used to train them. Some of the data used in the datasets to train AI models are public domain data.
- But, a good part of the data used in these datasets belongs to living artists that have not declared it to be public domain data.
- These are artists that make their living by selling such data (selling their decades of hard work that have produced a specific style and a series of works).
- These artists are, indeed, the foundation on which this revolution is supporting itself on its meteoric rise. And so, an increasing chorus of living artists are complaining about this. Some of them state that the works of living artists should not be included in these datasets. According to some, their complaints have fallen on deaf ears, largely being ignored (at least so far).
- I will always support generative AI, but above all, I will support and defend my fellow creatives (because people and their lives should always matter more than technology).
That’s it! I hope you enjoyed this article. In the following, we will look further into applying the prompt book to real data visualisation projects, and share some first hints of working with AI video creation and data. If you are interested in this, subscribe to our data newsletter!

